Ingest and retrieve semantic data
The ability to scrape, chunk, and upsert in one place.





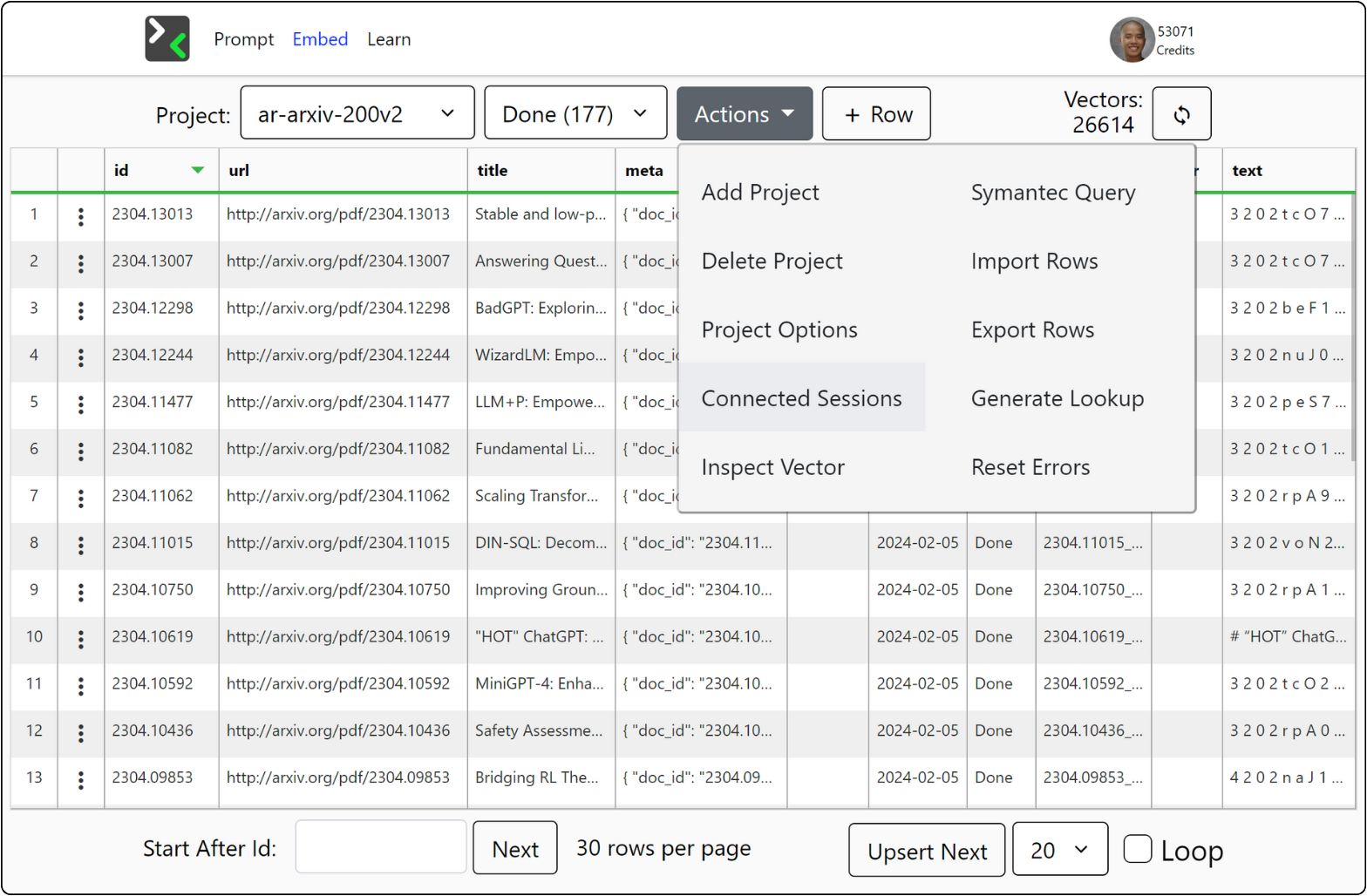
Streamlined Data Workflow
Everything to build knowledgeable AI in one user-friendly GUI.
- Document Upserter: enhance data import into Pinecone with automatic ID generation for documents and chunks, alongside efficient error handling, for seamless integration.
- Import Options: scrape the web or upload from CSV or JSON files.
- Custom Metadata: utilize custom metadata fields for enriched context and search capabilities.
- Cloud Lookup: an index that maps vector IDs to original texts, facilitating easy text retrieval out of the box
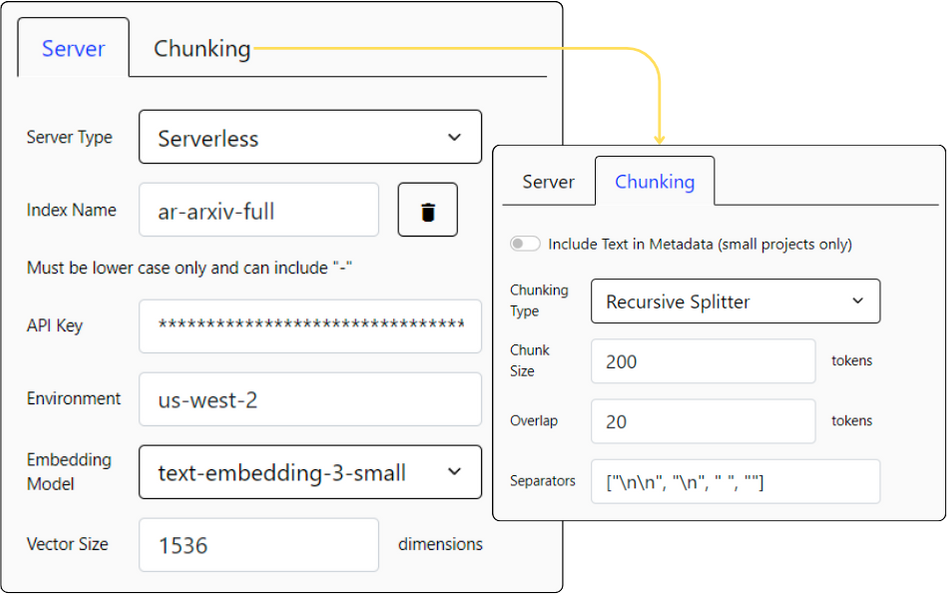
Customizable Data Processing
Streamline AI data handling with our precise, flexible processing features
- Chunking: customize data segmentation with sentence or token counts.
- Overlapping: maintain continuity across segments with overlapping chunks.
- Include Metadata: text in metadata for smaller projects, enabling efficient text retrieval within space limits.
- Configuration: choose from server-based or serverless options to match your project's infrastructure needs.
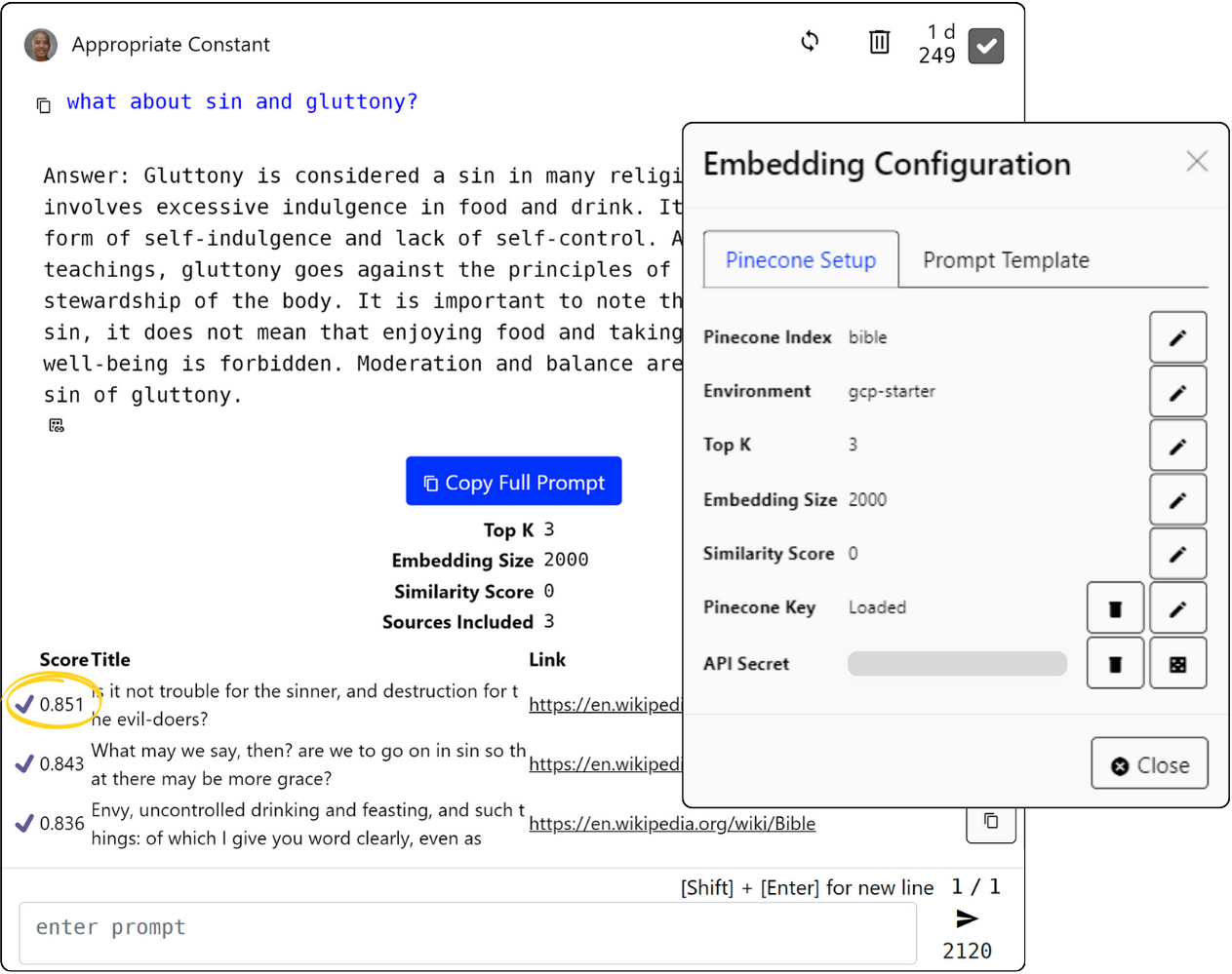
Prompt templates that embed semantic results
Connected sessions allow for immediate testing and integration of semantic retrieval.
- Embed Template: change what content to inject as context or referenced as details.
- Embedding Details: access critical semantic details, such as similarity scores and metadata, within your chat interface.
- Limit Embedding: adjust the embedding limit to control number of semantic results injected into your prompt.

Building Semantic Retrieval Systems
Use Embed as an independent tool or alongside the Unacog API.
Standalone Solution: simplifies semantic retrieval setup by streamlining data processing and text lookup, offering all required exports for retrieval tasks
Unacog APIs: integrate with Unacog's sessions for managed vector querying and/or LLM messaging.
About the Demo Applications (and Code!)

Semantic search examples are powered by the Unacog API.
- Unacog API: session management through Unacog involves billing, configuration, and secure API authentication with revocable keys.
- Vector Search: enables querying of similar vector results for any prompt, returning top K results based on cosine similarity scores.
- LLM Message: used for sending prompts to the LLM, supporting both direct submission and pre-processed embedding.
- GitHub Repo: view the code at unacogdemo
Ready to get started?
Connect with us for a no-charge discovery consultation.